本ページ内での定義
df = DataFrame
Val = Variables 連続値
Gval = Grouping variables グループ分けして視認可能な 離散値 | オブジェクト
ライブラリの読み込み
import pandas as pd
pd.plotting.register_matplotlib_converters() # datetime型のデータを扱う場合
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
print("Setup Complete")
共通パラメータ
data = pandas.DataFrame, numpy.ndarray, mapping, or sequence
x, y = vectors or keys in data
hue = Gvalを色合いで区別
legend = 凡例 “auto”, “brief”, “full”, or False
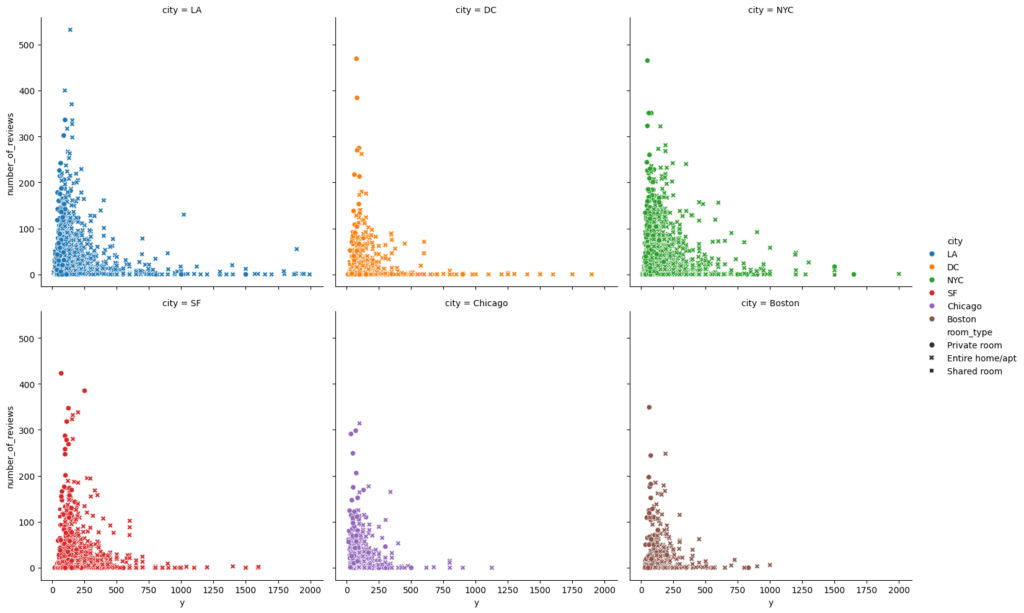
散布図
sns.relplot() x=Val, y=Val
size = Valの量をマーカーの大きさで表現
style = Gvalをマーカーで区別(●×■◆▲…)
col = Gval毎にsubplotを生成
col_wrap = 1行毎のsubplotの数
sns.relplot(data=df, x="Val", y="Val", hue="Gval", size="Val", style="Gval", col="Gval", col_wrap=num)
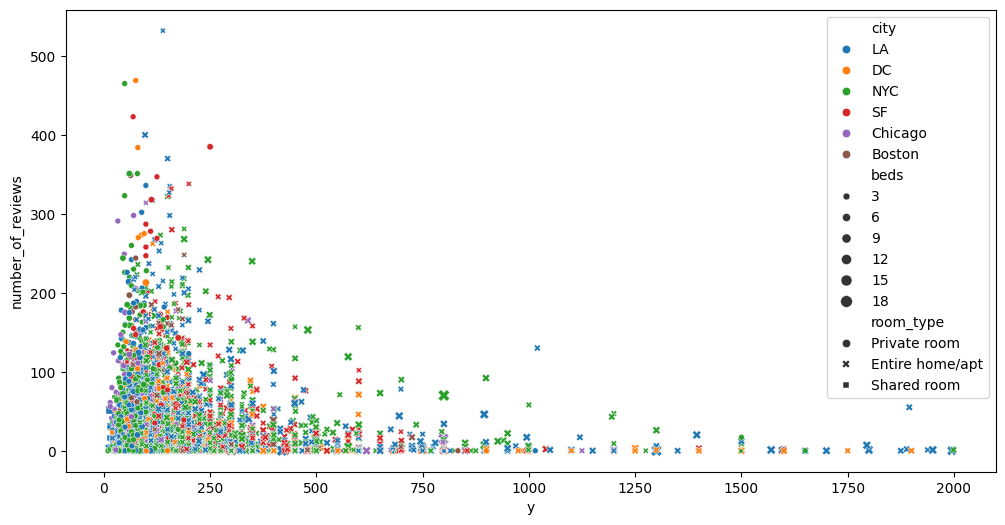
sns.scatterplot() x=Val, y=Val
size = Valの量をマーカーの大きさで表現
style = Gvalをマーカーで区別(●×■◆▲…)
plt.figure(figsize=(12,6)) sns.scatterplot(data=df, x="Val", y="Val", hue="Gval", size="Val", style="Gval")
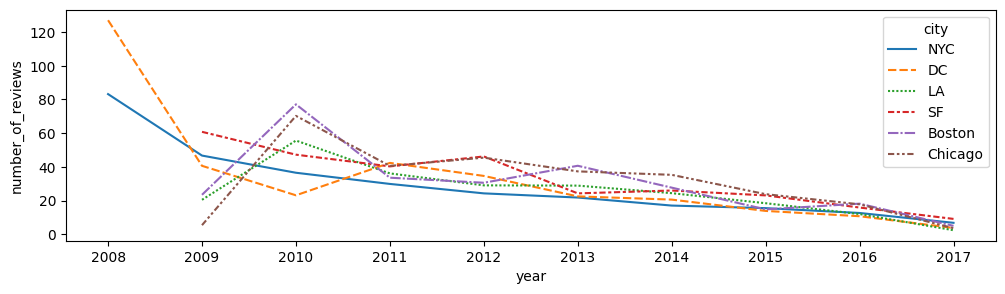
折れ線グラフ
sns.lineplot() x=Gval, y=Val
style = Gvalをマーカーで区別(●×■◆▲…)
markers = True / False(None) マーカーの表示 / 非表示
dashes = True / False(None) Gval毎に線種を変える / 変えない
err_style* = “band” / “bars” / None 誤差範囲を 範囲表示 / 縦線表示 / 非表示
plt.figure(figsize=(12,3)) sns.lineplot(data=df, x="Gval", y="Val", hue="Gval", style="Gval", markers=boolean, dashes=boolean, err_style=None*)
複合
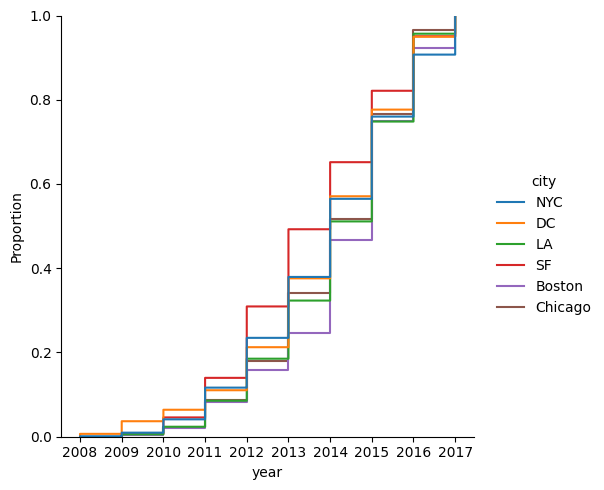
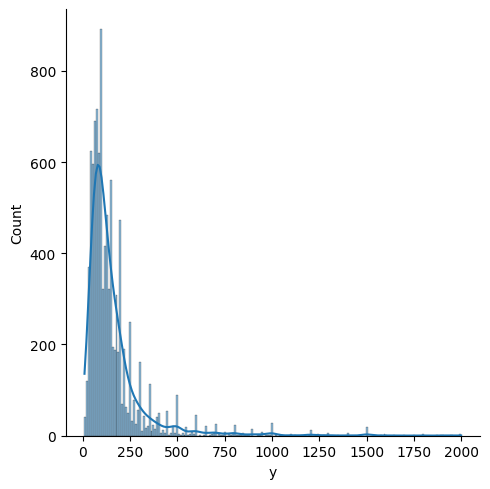
sns.displot() x=Val, y=Val
kind = “hist”(ヒストグラム) / “ecdf”(経験的累積分布関数)
kde = True kde(カーネル密度推定) 追加表示
sns.scatterplot(data=df, x="Val", y="Val", hue="Gval", kind="hist/ecdf", kde=boolean)
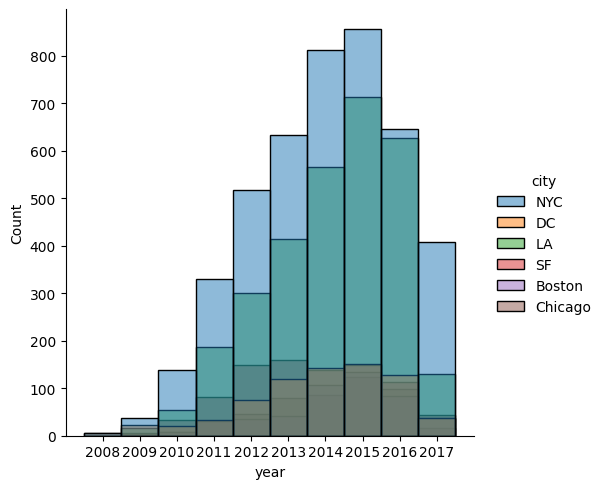
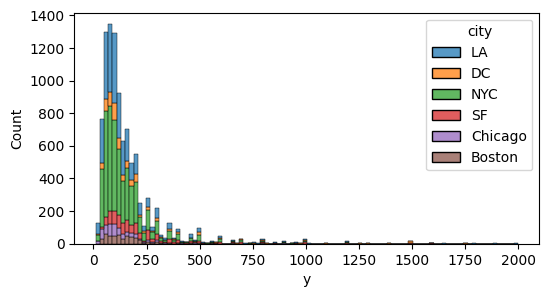
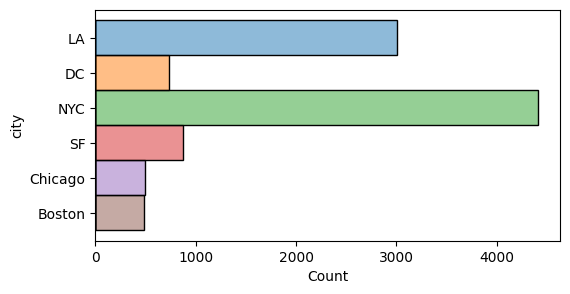
ヒストグラム
sns.histplot() x, y = Val / Gval
bins = num x軸の分割数
multiple* = layer / stack / fill / dodge
plt.figure(figsize=(12,3)) sns.histplot(data=df, x/y="Val/Gval", hue="Gval", bins=20, multiple="stack"*)