スタンス
人間 = 知的活動、新しい着想・アプローチ
鳥の目、獣の目、虫の目、魚の目、蝙蝠の目
原理/公理・定理を知り、方法論を学ぶ
事象を言語化・可視化して伝達・共有
参考)Interpretable Machine Learning
日本語版
機械 = 効率・効果を最大化するツール
アルゴリズムを理解し、使いこなす
ツールとしてのプログラミング言語
スニペットによる効率化
圧倒的な速さの重み付け、推論、評価
CRISP-DM 出展:IBM
(CRoss-Industry Standard Process for Data Mining)
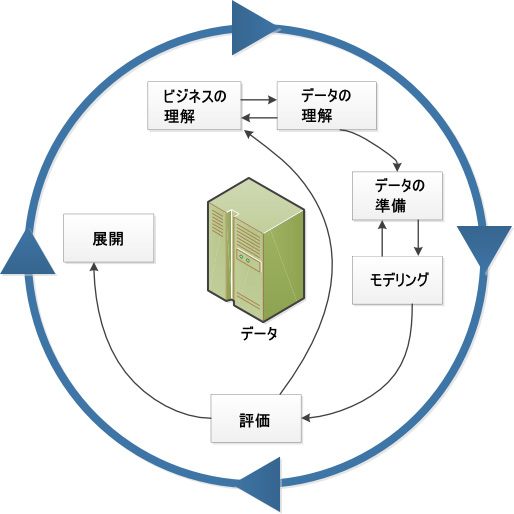
Business Understanding Data Understanding
Data Preparation
Deployment Modeling
Evaluation
自己流CRISP-DM
理解フェーズ
1)目的、タスクを理解
解決したい課題(解くべき問題)を正しく理解する
ビジネス上のKPIと機械学習の目的は同じゴールを向いているか
タスクの種類
回帰、二値分類、多値分類
2)一般常識、ドメイン知識を動員してデータセットを理解 <スピード重視>
データセット俯瞰
学習/検証に耐えられる説明変数か(レコード数・欠損値数・内容・データ型など)
使いたいがそのままでは使えない説明変数をどう料理するか
目的変数の特徴
データ型、件数
数値:分布、mean, std, min, 25%, median, 75%, max
カテゴリ値:内訳(value_counts)
説明変数と目的変数の相関
目的変数と相関がありそうな説明変数に目星をつける
▼相関が高い説明変数同士を複数選定するとモデルの精度が落ちやすいらしい
3)簡易的に推論 <スピード重視>
簡易的な欠損処理(穴埋め/ドロップ)・LE程度にとどめる
アルゴリズムを最低2つは選定
Hold-Out法/交差検証
依存度の高い説明変数の把握
4)仮説を立てる
EDAフェーズ
1)説明変数を分析 <スピード重視>
説明変数の特徴
データ型、件数
数値:分布、mean, std, min, 25%, median, 75%, max
カテゴリ値:内訳(value_counts)
依存度の高い説明変数を考察(視点・組合せを変えて可視化)
自分が着目した説明変数を考察(視点・組合せを変えて可視化)
説明変数を絞ってHold-Out法/交差検証
初回評価と比較
2)説明変数を吟味 <クオリティ重視>
目星をつけた説明変数について欠損値処理・外れ値処理・エンコーディング手法の検討
欠損値処理 : ドロップ可否判定(NaNが意味を持つ場合は特に注意)
外れ値処理 : ドロップ可否判定、スレッショルドの調整
エンコーディング:ダミー変数化
説明変数を変えてHold-Out法/交差検証
これまでの評価と比較
汎化性能向上フェーズ
1)特徴量エンジニアリング
合体させて新たな説明変数の作成を検討
先人の知恵を探索(書籍、メディア、分析系サイト、コンペサイトのディスカッション等)
外部オープンデータの利用を検討
2)スケール調整
正規化
サンプリング
3)アルゴリズム選定
4)ハイパーパラメータの調整
5)アンサンブル学習