理解フェーズ
アメリカ国内6都市の民泊施設データ SIGNATEリンク
タスク :回帰
目的 :民泊物件データを使って宿泊価格(US$)を予測
評価指標:RMSE
近年、Airbnb(エアビー)のシェア拡大により、個人の家を丸ごと借りたり、一部屋を借りたりして、現地のライフスタイルに少し触れることができる滞在が可能になりました。
宿泊の料金は、場所や規模にも寄りますが、都市部で、1ベッドルームを借りるとホテルの一部屋分と同等または少し高いぐらいのところが多く(宿泊費に追加でクリーニング費が掛かるため)、3ベッドルームなどを借りるとAirbnbの方が安くなる傾向があるようです。
# 使用するライブラリ import pandas as pd import numpy as np import matplotlib.pyplot as plt %matplotlib inline import seaborn as sns from sklearn.preprocessing import LabelEncoder from sklearn.model_selection import train_test_split, GridSearchCV, KFold, StratifiedKFold, cross_val_score from sklearn.ensemble import RandomForestRegressor as RFR from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score import xgboost as xgb import lightgbm as lgb import catboost
データセット俯瞰
各カラムの意味 ※注意:Web掲載と実際とではdtypeが違うカラムもあるようだ
| dataset | shape |
|---|---|
| train.csv | (55583, 29) |
| test.csv | (18528, 28) |
train.info(all) RangeIndex: 55583 entries, 0 to 55582 Data columns (total 29 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 id 55583 non-null int64 1 accommodates 55583 non-null int64 2 amenities 55583 non-null object 3 bathrooms 55436 non-null float64 4 bed_type 55583 non-null object 5 bedrooms 55512 non-null float64 6 beds 55487 non-null float64 7 cancellation_policy 55583 non-null object 8 city 55583 non-null object 9 cleaning_fee 55583 non-null object 10 description 55583 non-null object 11 first_review 43675 non-null object 12 host_has_profile_pic 55435 non-null object 13 host_identity_verified 55435 non-null object 14 host_response_rate 41879 non-null object 15 host_since 55435 non-null object 16 instant_bookable 55583 non-null object 17 last_review 43703 non-null object 18 latitude 55583 non-null float64 19 longitude 55583 non-null float64 20 name 55583 non-null object 21 neighbourhood 50423 non-null object 22 number_of_reviews 55583 non-null int64 23 property_type 55583 non-null object 24 review_scores_rating 43027 non-null float64 25 room_type 55583 non-null object 26 thumbnail_url 49438 non-null object 27 zipcode 54867 non-null object 28 y 55583 non-null float64 dtypes: float64(7), int64(3), object(19)
test.info(all) RangeIndex: 18528 entries, 0 to 18527 Data columns (total 28 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 id 18528 non-null int64 1 accommodates 18528 non-null int64 2 amenities 18528 non-null object 3 bathrooms 18475 non-null float64 4 bed_type 18528 non-null object 5 bedrooms 18508 non-null float64 6 beds 18493 non-null float64 7 cancellation_policy 18528 non-null object 8 city 18528 non-null object 9 cleaning_fee 18528 non-null object 10 description 18528 non-null object 11 first_review 14572 non-null object 12 host_has_profile_pic 18488 non-null object 13 host_identity_verified 18488 non-null object 14 host_response_rate 13933 non-null object 15 host_since 18488 non-null object 16 instant_bookable 18528 non-null object 17 last_review 14581 non-null object 18 latitude 18528 non-null float64 19 longitude 18528 non-null float64 20 name 18528 non-null object 21 neighbourhood 16816 non-null object 22 number_of_reviews 18528 non-null int64 23 property_type 18528 non-null object 24 review_scores_rating 14362 non-null float64 25 room_type 18528 non-null object 26 thumbnail_url 16457 non-null object 27 zipcode 18278 non-null object dtypes: float64(6), int64(3), object(19)
目的変数:y 宿泊料金
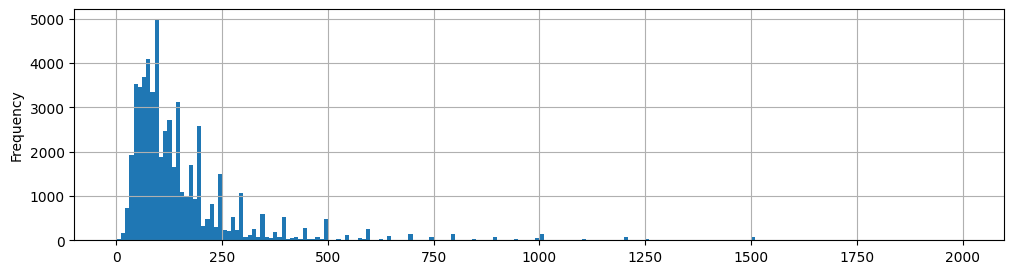
料金分布:全体
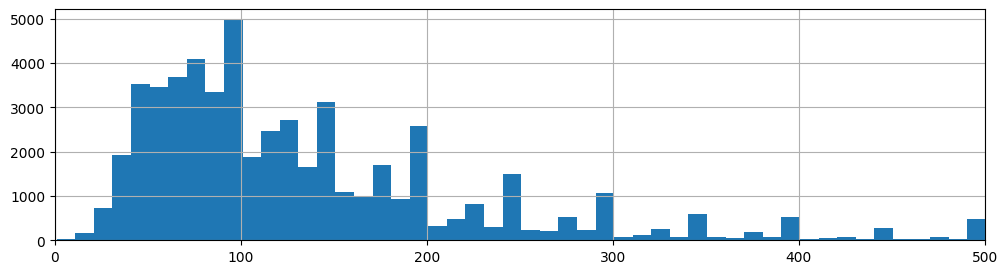
料金分布:分布が集中する$0~$500にフォーカス
料金分布:高額な$1,000~$2,000にフォーカス
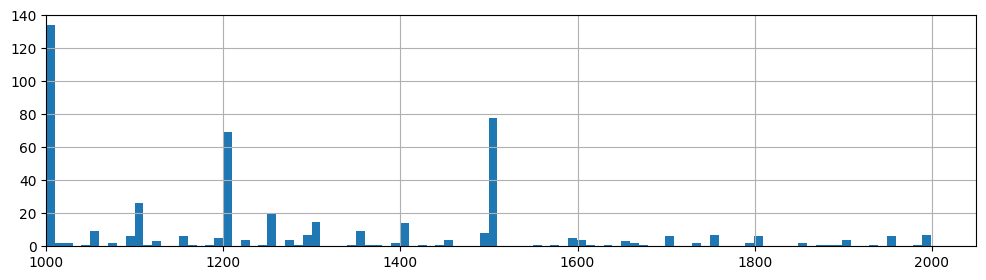
・大半が$50~$200の価格帯に分布している。
・少数だが$1,000以上の高額物件もある。高額物件もきちんと予測できるモデルを作りたい。
目的変数との相関
カラムを絞り、欠損値をばっさり消去、カテゴリ値をラベルエンコードした簡易なDataFrameを使用
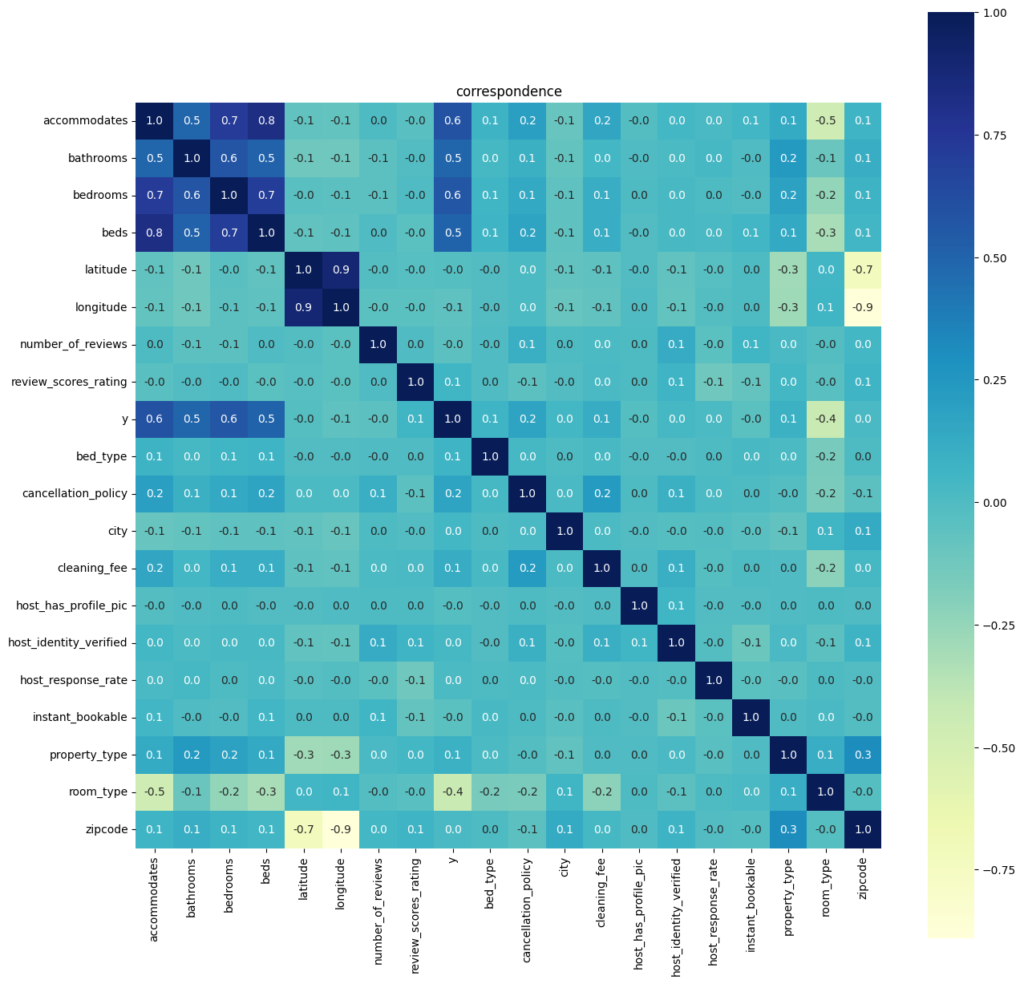
yと相関が強いのは
(正)accommodates, bathrooms, bedrooms, beds, 若干cancellation_policy※
(負)room_type※ ※カテゴリ変数のLEなので参考値
accommodates, bathrooms, bedrooms, beds は説明変数同士の相関が強い
ホスト、利用者どちらにも共通すると思われる「立地」は相関が弱い
「立地」に関わるものは city, latitude, longitude, neighbourhood あたりか?
簡易的に推論
先ほど相関を見た時に使用したDataFrameを、下記の条件で簡易推論
データ分割:
アルゴリズム:
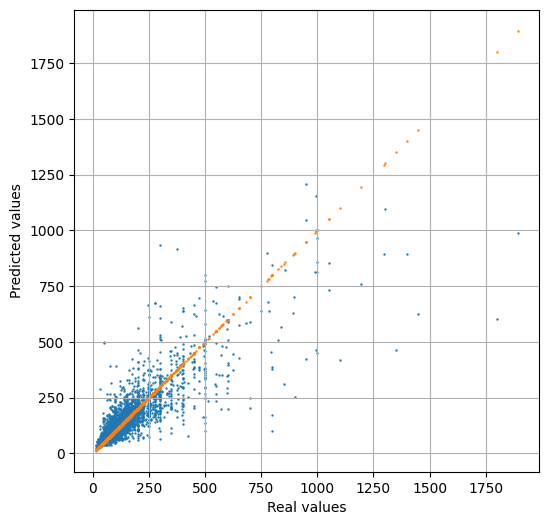
RandomForest結果
MAE: 41.19128950338601
MSE: 6409.077354599324
RMSE: 80.05671336371063 (^^;)
相関係数R : 0.8156364315848796
決定係数R2: 0.6652627885285161
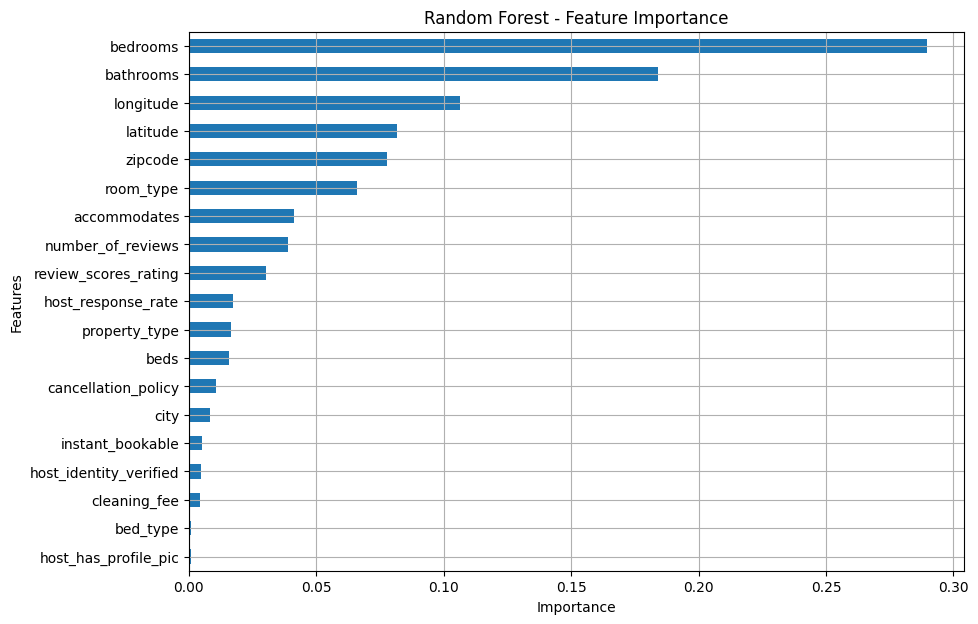
重要度(右図)
・説明変数同士の相関が強いものは絞った方がいいのかも?
・緯度経度や郵便番号の重みが高い…これはちょっと意図とズレているかも。。
仮説
(ホスト目線)実際は何を基準に宿泊料を設定するだろうか?
立地(人気エリア・利便性)、設備の質、サービスの質
(利用者目線)宿を選ぶ時、料金以外に何を気にする?
立地(人気エリア・利便性)、口コミ(レビュー点数)、レビュー内容、写真
※日本なら風呂は貸し切りか、風呂付の部屋かとか気にするが…場所はアメリカ。
・ホスト目線からも利用者目線からも共通する最重要要素
立地
city 都市
neighbourhood 近隣情報
latitude 緯度
longitude 経度
zipcode 郵便番号
・料金設定に直接影響しそうな要素
設備の質
accommodates 収容可能人数
bed_type ベッドの種類
amenities アメニティ
property_type 物件の種類
room_type 部屋の種類
サービスの質
cancellation_policy キャンセルポリシー
host_response_rate ホストの返信率
thumbnail_url サムネイル画像リンク
課題
・「立地」とは言っても、人気エリアや利便性の判定をどう行うか?
city毎の概要、neighbourhoodから特徴的な文字列の抽出
latitude, longitudeで所在地を地図にプロットして特徴が見出せるか
鉄道駅の座標を取り込んで最寄り駅からのマンハッタン距離を算出 など
・特徴量として使用したいが欠損値が多いカラム
host_response_rate(欠損 13,704)サービス品質に関わる事項
neighbourhood(欠損 5,160)立地に関わる事項
・加工しなければ使えないカテゴリ変数
amenities, neighbourhood 頻出文字を抽出してダミー変数化
thumbnail_url URLが有る/無いこと自体に意味があるのでダミー変数化
EDAフェーズ
説明変数を分析
train.city
都市別の平均金額(全件/1,000ドル未満で対象を変え、平均値と中央値を見る)
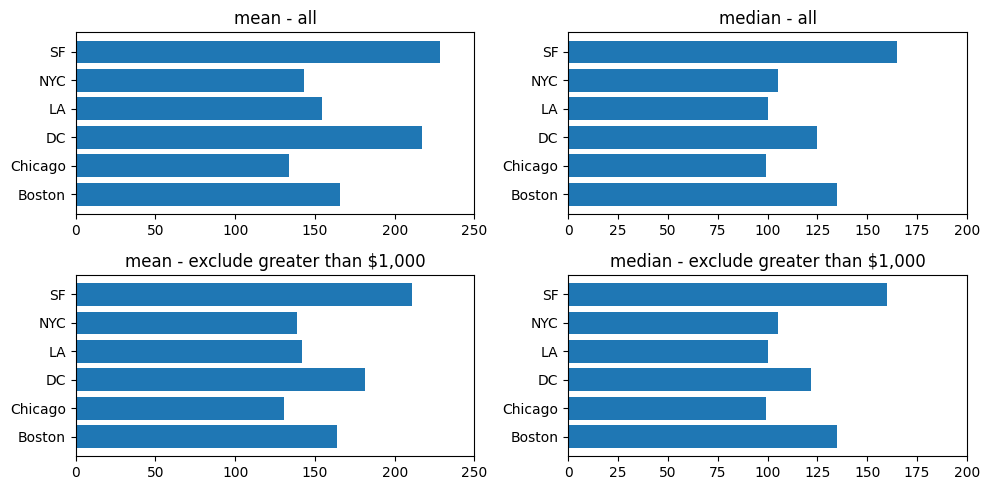
・1,000ドル以上を除くと、都市によって平均額のバランスが少し変わる。
アンバランスなのであれば、1,000以上を外れ値と見なすべきだろうか。
都市ごとの料金分布
| city | y | |||
|---|---|---|---|---|
| min | median | mean | max | |
| Boston | 17.0 | 135.0 | 165.629287 | 1400.0 |
| Chicago | 10.0 | 99.0 | 133.935162 | 1500.0 |
| DC | 10.0 | 125.0 | 217.383658 | 1999.0 |
| LA | 10.0 | 100.0 | 154.555324 | 1995.0 |
| NYC | 1.0 | 105.0 | 143.096152 | 1999.0 |
| SF | 10.0 | 165.0 | 228.389471 | 1995.0 |
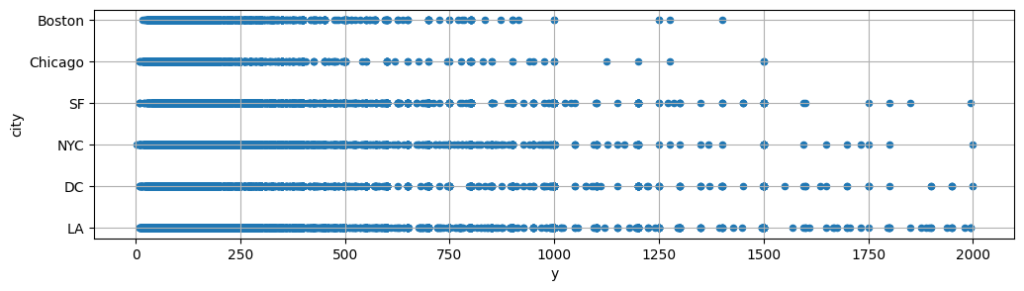
・Boston、Chicagoには $1,500以上の物件がない
・SF, NYC, DC, 特にLA には $1,500以上の物件がそこそこある -> 外れ値として除外すると乱暴かも