スケーラビリティ
垂直方向 スケールアップ / ダウン ※スペックを上げる
RDSやElastiCacheは、垂直方向に拡張できるサービス
変更前:t2.nano 0.5G RAM | 1vCPU
変更後:u-12tb.metal 12.3TB RAM | 448 vCPU
水平方向 スケールアウト / イン(=弾力性:elasticity) ※数を増やす
分散システムの考え方 水平方向に簡単に拡張できる=クラウドの最大のメリット
・オートスケーリンググループ
・ロードバランサ―
高可用性(High availability)
・オートスケーリンググループ マルチAZ
・ロードバランサ― マルチAZ
ロードバランサーは、インターネットのトラフィックを下流の複数のサーバ(EC2)に転送するサーバ
ヘルスチェックは不可欠!
ポートとルートで行われる(/healthが一般的)
レスポンスが200OKでなければ、そのインスタンスは不健全と判断 → ASGでは自動でインスタンスを終了したり
ロードバランサーにセキュリティグループをアタッチして、セキュリティを担保する
ロードバランサ―自体をスケールアップできる(2~5分かかるのでAWSに連絡してウォームアップが必要だろう)
トラブルシューティング
400番台 クライアントエラー
500番台 アプリケーション(サーバ)エラー
503は容量不足または登録されたターゲットが無いことを意味する
モニタリング
ELBのアクセスログはすべてのアクセスリクエストを記録しているので、リクエストごとにデバックが可能
CloudWatch Metricsでは集約された統計情報(例:コネクション数)が得られ、それをポリシーとして利用可能
CLB(Classic Load Balancer)v1 2009年 非推奨
対応プロトコル:HTTP/1.1、HTTPS、TCP
ヘルスチェック:インスタンスごと(TCPまたはHTTPベース)
固定ホスト名:xxx.region.elb.amazonaws.com
アプリケーションごとに複数のCLBが必要となる
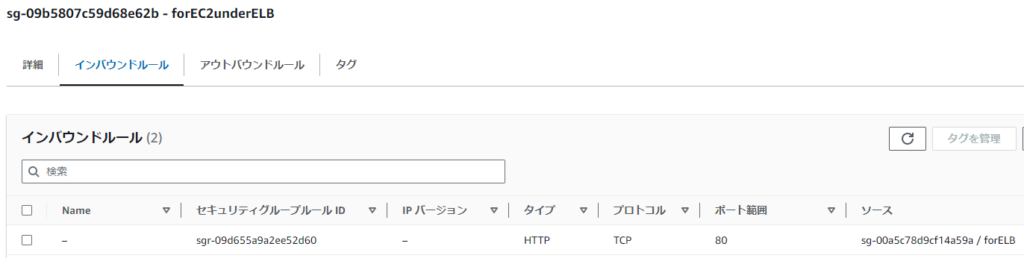
設定例>インスタンス3台(同じAZ内に配置)

設定例>CLB(3台をターゲットインスタンスとして登録)
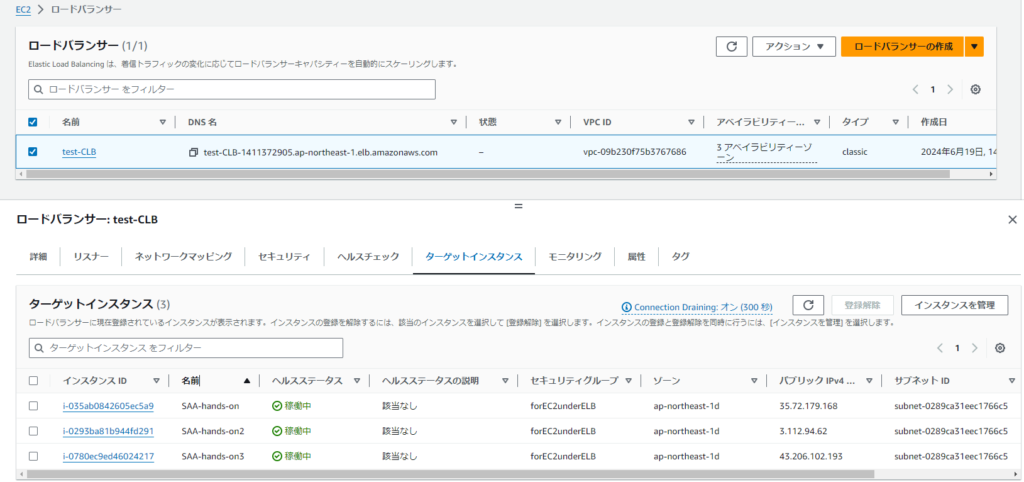
設定例>CLBにアタッチするセキュリティグループ(HTTP80からアクセス許可)
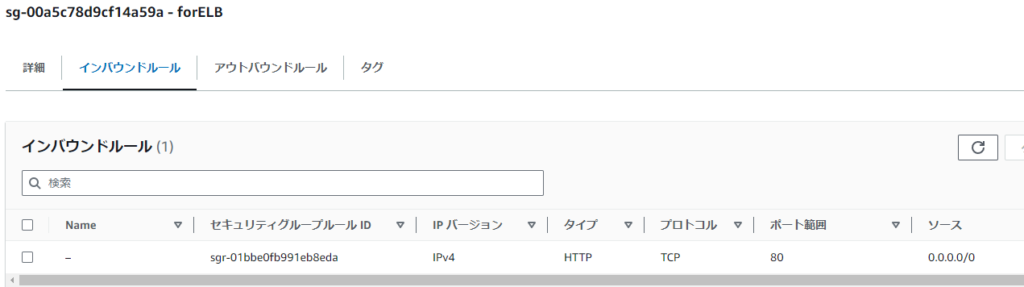
設定例>CLB配下のEC2にアタッチするセキュリティグループ(LB経由のアクセスのみ許可)
ALB(Application Load Balancer)v2 2016年
対応プロトコル:HTTP/1.1、HTTPS、HTTP/2、WebSocket
ヘルスチェック:ターゲットグループごと
固定ホスト名:xxx.region.elb.amazonaws.com
ターゲットグループで管理(複数のHTTPアプリ、複数のマシンに対してロードバランシング 例:コンテナ)
EC2インスタンス(Auto Scaling Groupで管理)- HTTP
ECSのタスク(ECS自身が管理するもの)- HTTP
ラムダ関数 – HTTPリクエストがJSONイベントに変換される
プライベートIPアドレス
ルーティングテーブルで異なるターゲットグループに振り分け可能
URLのパスに基づいたルーティング(example.com/users, example.com/posts)
URLのホスト名に基づいたルーティング(one.example.com, other.example.com)
クエリ文字列、ヘッダーに基づいたルーティング(example.com/users?id=123&order=false)
※マイクロサービスやコンテナベースのアプリに適している(DockerとAmazonECS)
リダイレクトをサポート(HTTPからHTTPSへの変更など)
ECSの動的ポート割り付けにリダイレクトするポートマッピング機能
クライアントのIPを直接見ることはないが、クライアントの真のIP情報は、ヘッダのX-Forwarded-xxxに挿入される
X-Forwarded-For IPアドレス
X-Forwarded-Port ポート番号
X-Forwarded-Proto プロトコル(TCP/UDPだろう)
設定例>ALB(リスナーとしてHTTP:80を登録し、ターゲットグループへ転送をアクション指定)
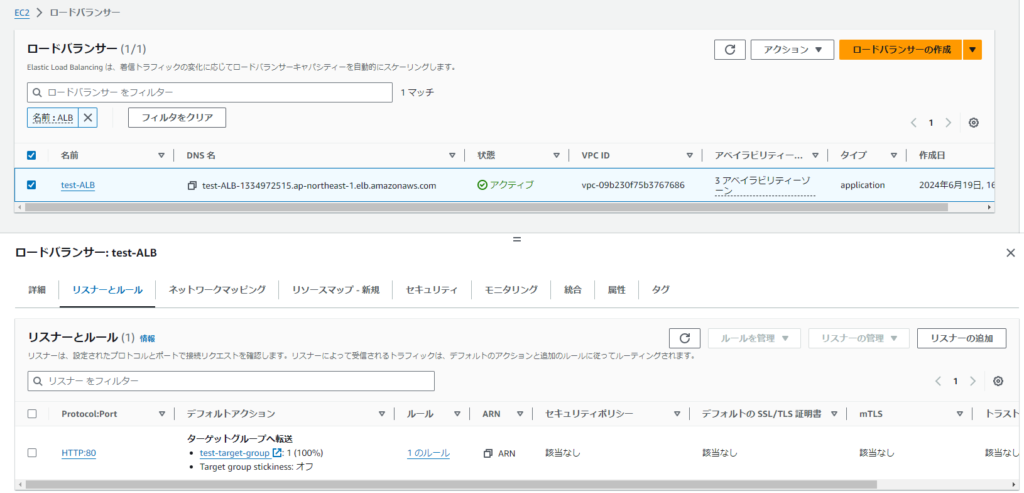
設定例>ターゲットグループ(HTTPプロトコル)に3台を登録する
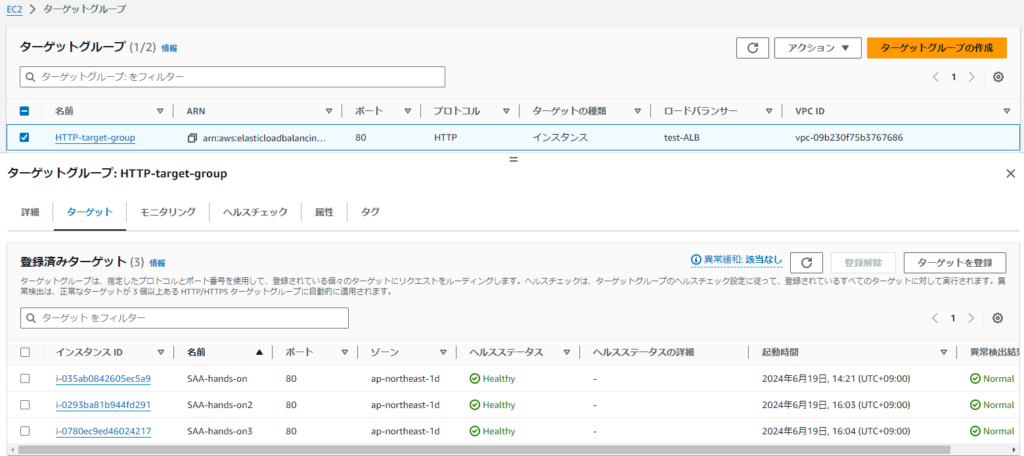
※セキュリティグループはCLBの時と同様
ALBにアタッチするセキュリティグループ(HTTP80からアクセス許可)
ALB配下のEC2にアタッチするセキュリティグループ(LB経由のアクセスのみ許可)
NLB(Network Load Balancer)v2 2017年
対応プロトコル:TCP、SSL/TLS(セキュアTCP)、UDP
ヘルスチェック:ターゲットグループごと
AZごとに1つの静的IPを持つ Elastic IPの割当も可能(IPアドレスベースのホワイトリスト作成に便利)
Free Tier(無料利用枠)には含まれない
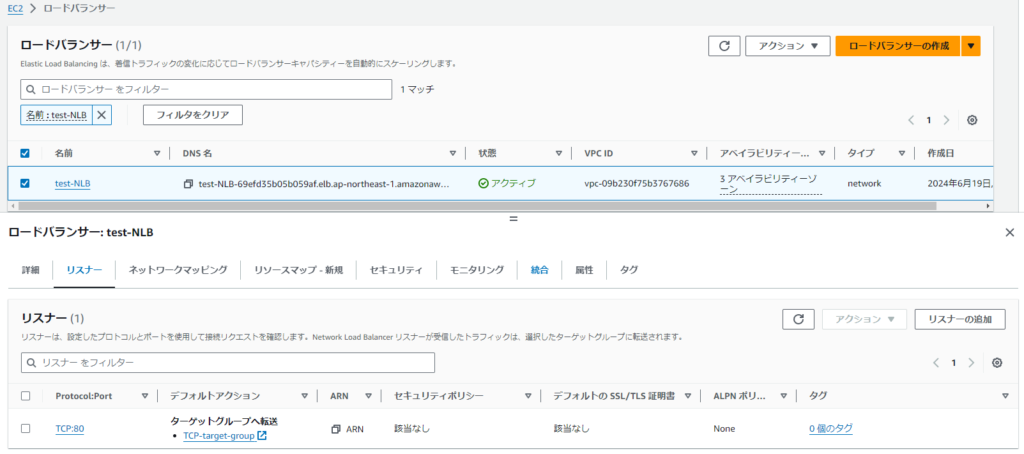
設定例>NLB(リスナーとしてTCP:80(つまりHTTP)を登録し、ターゲットグループへ転送をアクション指定)
設定例>ターゲットグループ(TCPプロトコル)に3台を登録する
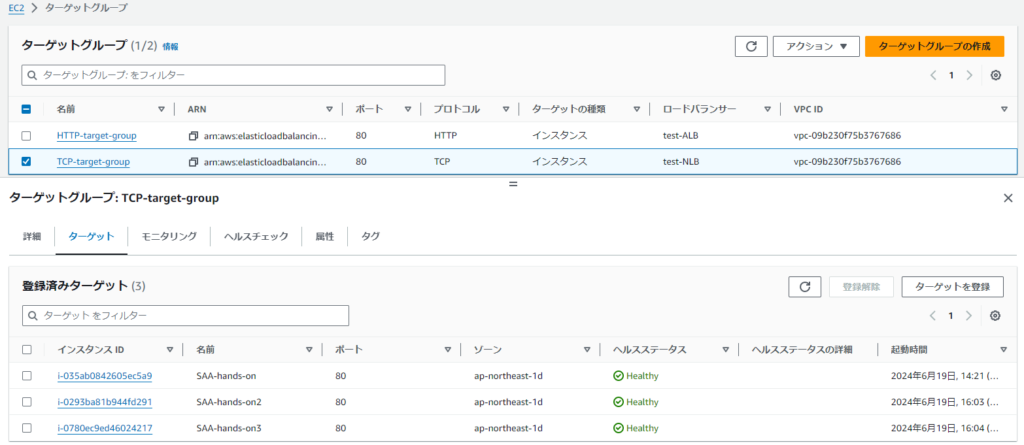
※セキュリティグループはCLBの時と同様
ALBにアタッチするセキュリティグループ(HTTP80からアクセス許可)
ALB配下のEC2にアタッチするセキュリティグループ(LB経由のアクセスのみ許可)
スティッキーセッション ▼要注意
同じクライアントが、常に同じインスタンスにリダイレクトされるようにすること
cookieを利用する(cookie有効期限を設定できる)
ALBで利用可能(CLBじゃ設定できないじゃん)
ターゲットグループで設定する(ほらCLBじゃ無理じゃん)
使用例:ユーザーがセッションデータを失わないようにする
注意点:バックエンドのEC2インスタンスの負荷が不均衡になる可能性がある(クライアント毎にリダイレクト先が固定されるため)
なんかやばそうな記事があったから、使わない方がいいのかも?
ALBのスティッキーセッション設定方法(機能を試すだけ)
ターゲットグループ>属性>編集
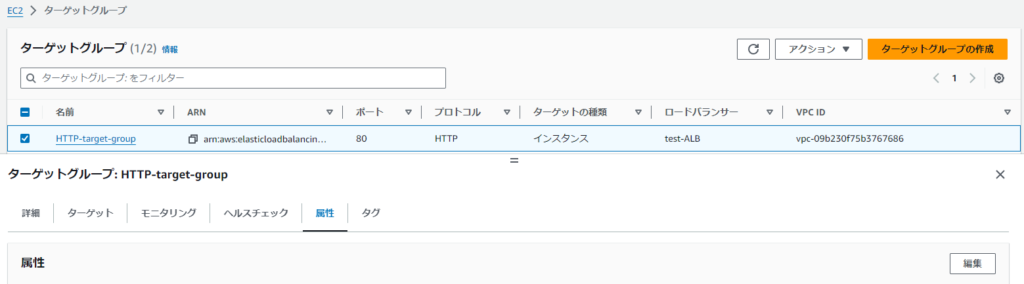
維持設定をオン>ロードバランサ―がCookieを生成しました>期間を設定
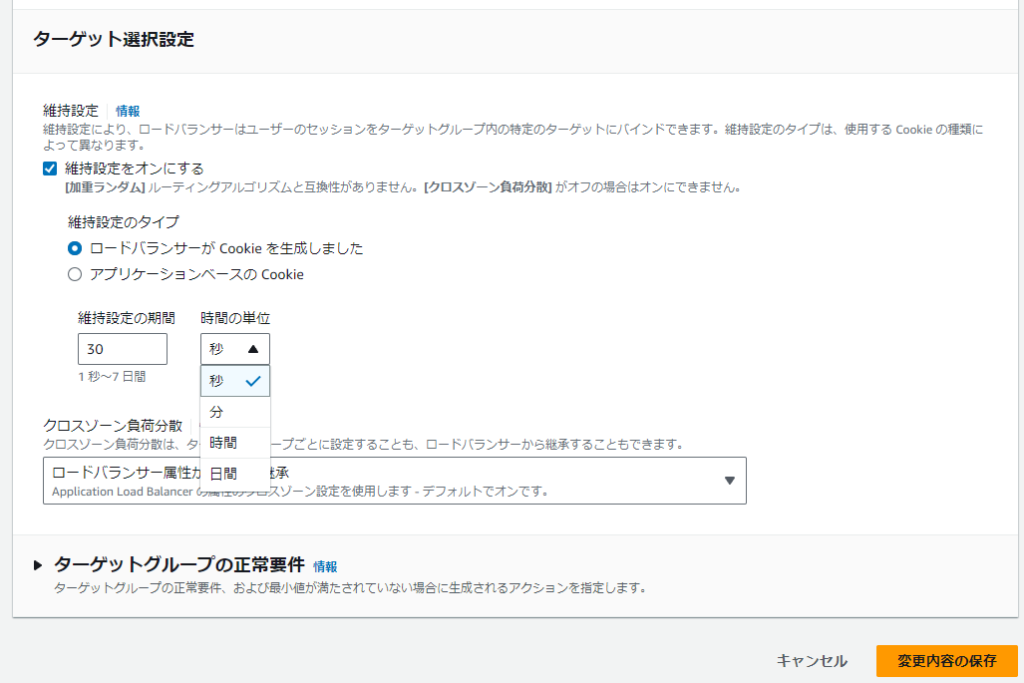
ということで、普段は使わないこと
クロスゾーンロードバランシング
CLB(Classic Load Balancer)
マネジメントコンソールで作成=>デフォルトで有効
CLI/API経由で作成=>デフォルトで無効
有効な場合、AZ間データの料金は不要
ALB(Application Load Balancer)
常時有効(無効化できない)
AZ間のデータ通信料は 無料
NLB(Network Load Balancer)
デフォルトでは無効
有効にした場合、AZ間のデータ通信料は 有料
SSL/TLS認証
SSL(Secure Sockets Layer)通信路のレガシー暗号化技術
TLS(Transport Layer Security)いまや標準はTLSなのに、未だに「SSL/TLS」どころか「SSL」と呼ばれている
パブリックSSL証明書は、認証局(CA)が発行:Comodo, Symantec, GoDaddy, GlobalSign, Digicert, Letsencrypt等
証明書には有効期限(作成者が設定)があって、更新する必要がある
クライアント ⇔ HTTPS over www ⇔【 ロードバランサ― 】⇔ HTTP over vpc ⇔ EC2インスタンス
ELBはX.509証明書を使用
ACM(AWS Certificate Manager)で証明書を管理することができる
独自の証明書を作成してアップロードすることも可能
※SSL証明書を発行するにはFQDN(完全装飾ドメイン名)が必要なので、おいそれと発行できなかった><;
HTTPSリスナー(デフォルトのSSL証明書を指定する必要あり)
複数ドメインに対応する時は、SNI(Server Name Indication)を使って到達するホスト名を指定する
SNI(Server Name Indication)
複数のSSL証明書を 1つのWebサーバーに搭載する ための技術(2003年)
クライアントは、最初のSSLハンドシェイクでターゲットサーバーのホスト名を示す必要がある
サーバーは、正しい証明書を見つけるか、デフォルトの証明書を返す
注意点
CLB(v1)では動作しない(1つのCLBに対し1つのSSL証明書しかサポートしていない)
ALB・NLB(v2)、CloudFrontでのみ動作する(複数のSSL証明書を持つ複数のリスナーに対応)
コネクションドレイニング
機能の名前
CLB:コネクションドレイニング
ALB&NLB:ターゲットグループ「登録解除の遅延」
インスタンスの登録解除中や不調時に「処理中のリクエスト」の完了を待つ時間(1~3,600秒、デフォ300秒)無効化も可
リクエストがすぐ完了する場合は低い値に設定しておこう
ASG(Auto Scaling Group)
実際のシステムではウェブサイトやアプリの負荷は常に変化する
サーバーの作成や処分を自動で迅速に行うための仕組み
できること
水平方向 スケールアウト/スケールイン(EC2インスタンスの増減)
最小限のマシンと最大限のマシンが稼働していることの確認
ロードバランサ―への新規インスタンスの自動登録(もちろんヘルスチェックも)
Maximum capacity 最大
Desired capacity 実際/希望
Minimum capacity 最小
ASGの属性
起動用の設定
※2023/5/31以降に作成されたアカウントでは、EC2 コンソールは「起動テンプレート」のみをサポート。
CLI と API で利用できていた「起動設定」は2023/12/31で廃止された。
AMI+インスタンスタイプ
EC2ユーザーデータ
EBSボリューム
セキュリティグループ
SSHキーペア
最小/最大/初期キャパシティ
NW+サブネットの情報
ロードバランサ―情報
スケーリングポリシー
オートスケーリングのアラーム
CloudWatchのアラームに基づいてスケーリングできる
アラームはメトリクス(平均CPU使用率などの”指標”)を監視
メトリクスは、ASGインスタンス全体から算出
アラームに基づいてスケールアウト/スケールイン
オートスケーリングの新ルール
EC2が直接管理する「より良い」自動スケーリングルールを定義できるようになった
目標とする平均CPU使用率
インスタンスごとのELBへのリクエスト数
平均ネットワーク入力/出力
オートスケーリング カスタムメトリクス
カスタムメトリクス(例:接続ユーザ数)に基づいてオートスケールすることができる
1.EC2上のアプリケーションからCloudWatchにカスタムメトリックを送信(PutMetric API)
2.CloudWatchのアラームを作成し、基準値(高・低)を設定
3.CloudWatchアラームをASGのスケーリングポリシーとして使用するよう設定
ASGの雑多な説明
スケーリングポリシーは、CPU・NWなどに加えて、カスタムメトリクスやスケジュールに基づいて設定することも可能
ASGは起動設定(Launch Configuration)または起動テンプレート(Launch Template:新しい)を使用している
ASGをアップデートするには、起動設定/起動テンプレートを新しくする必要がある
ASGに割り当てられたIAMロールがEC2インスタンスに割り当てられる
ASGは無料 ASGが起動するリソースには料金が含まれる
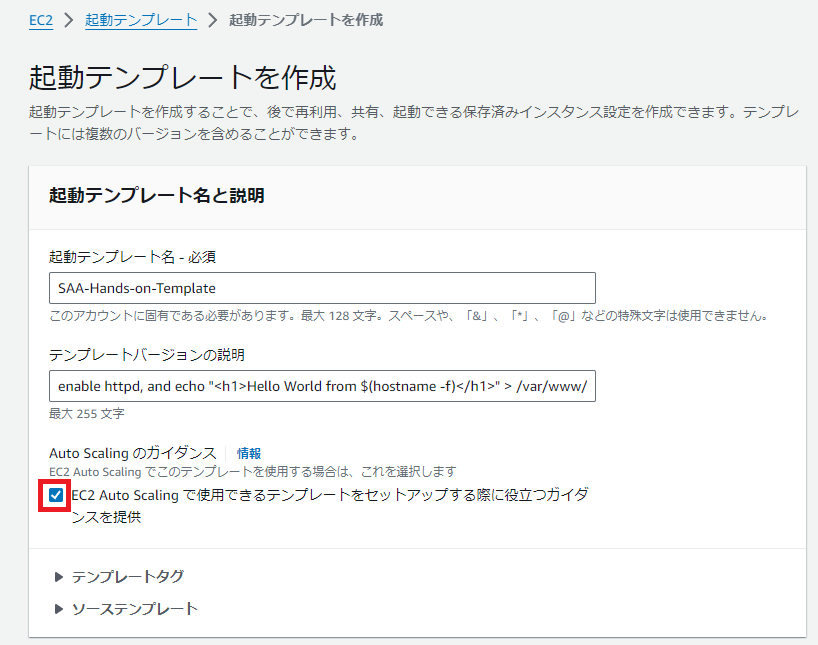
設定例> EC2インスタンス 起動テンプレート の作成
コツ①Auto Scaling のガイダンス にチェック
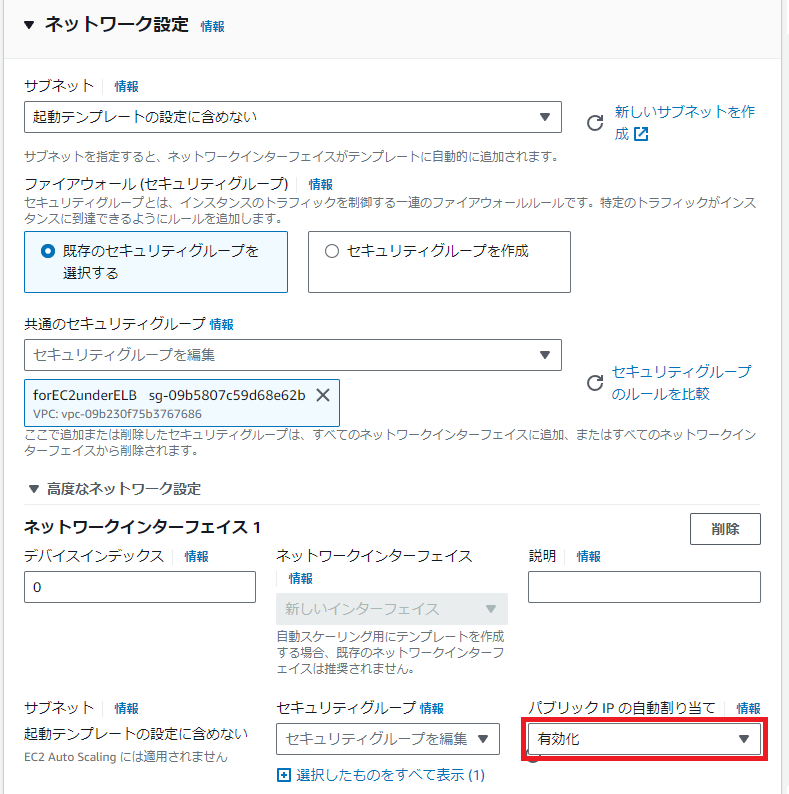
コツ②ネットワーク設定>高度なネットワーク設定>ネットワークインターフェースを追加>
パブリックIPの自動割り当て「有効化」
これ忘れると 503 Bad Gateway になるw
コツ③高度な詳細>ユーザーデータ にコマンド記述

設定例>Auto Scaling グループ の作成
コツ①追加のヘルスチェックタイプ>Elastic Load Balancingのヘルスチェックをオンにする にチェック
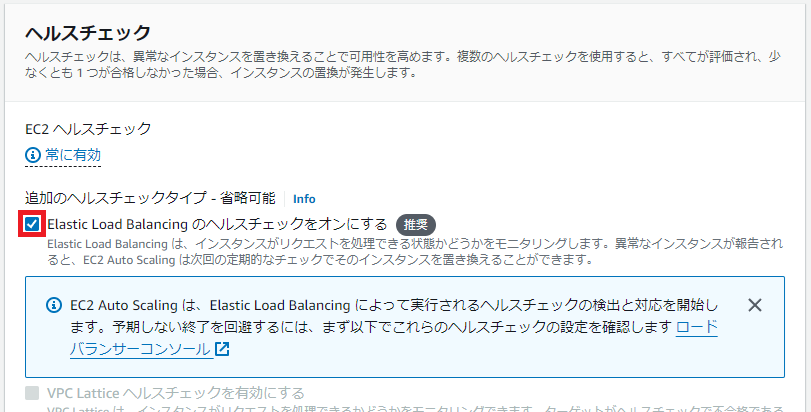
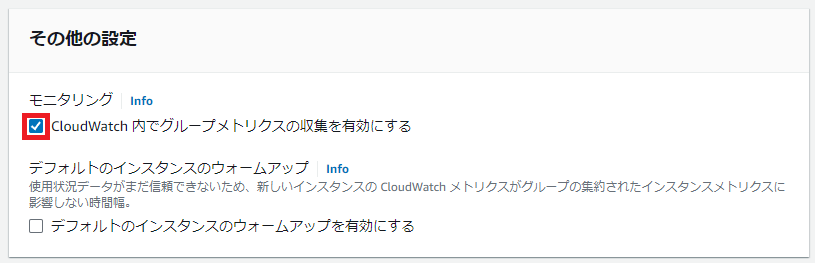
コツ②その他の設定>モニタリング>
CloudWatch内でグループメトリクスの収集を有効にする にチェック
これ忘れるとヘルスチェックで引っかかってEC2無限ループに陥るw
スケーリングポリシー
動的スケーリングポリシー
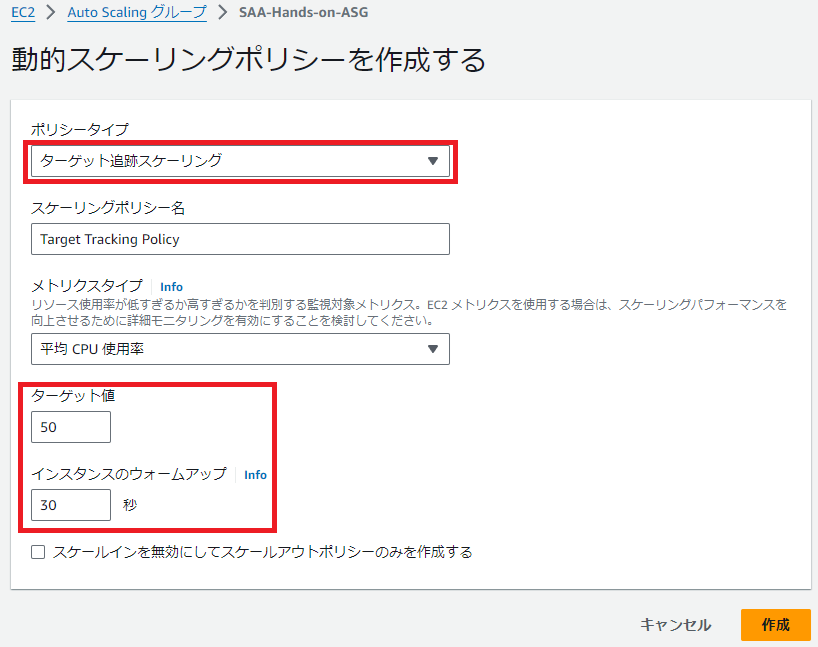
・ターゲット追跡スケーリング
最もシンプルで、セットアップが簡単
例:ASGのCPUの平均値を40%程度にしたい
・ステップスケーリング・シンプルなスケーリング
CloudWatchのアラームによって発動する
例:CPU使用率>70% の時 2台追加
CPU使用率<30% の時 1台削除
予測スケーリングポリシー
直近2日間/1~8週間の実績から予測して動く
予定されたアクション
希望する容量、最小容量、最大容量を少なくとも1つ決め、反復動作/タイムゾーン/開始時刻と共に
既知のアクセスパターン(トラフィックが輻輳しやすい曜日・時間帯等)に基づいて設定
例:金曜日の午後5時に、最小容量を10にする
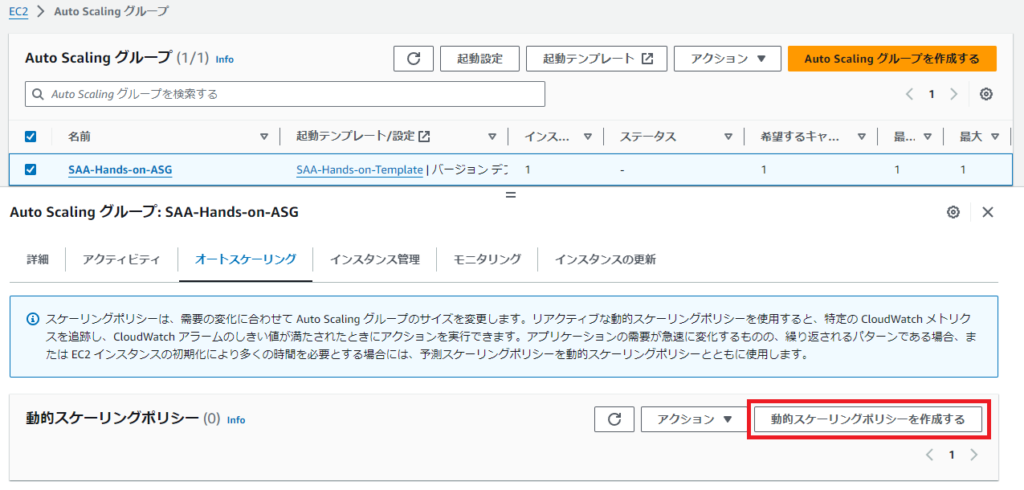
設定例>
ASG>オートスケーリング>動的スケーリングポリシー>ターゲット追跡スケーリング
スケールアウト・スケールインが始まる(CloudWatchのアラームが上がってASGが反応する)まで5分かかる!これは、CloudWatchの基本モニタリングがデフォルト5分間隔だから!
詳細モニタリング(1分間隔まで短縮できるみたい)を有効にすると、お金がかかるって><;でも、Free Tierで10個の詳細なモニタリング指標が使えるみたい!うお!一回スケールアウトが走ると、勝手に「希望するキャパシティ」が上がっちまう( ノД`)
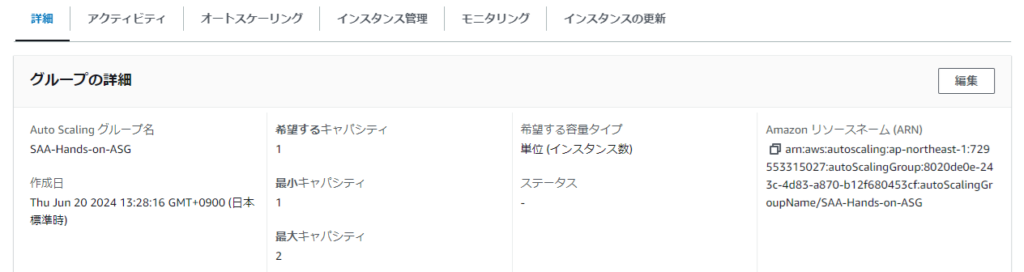
↓↓ げげ・・
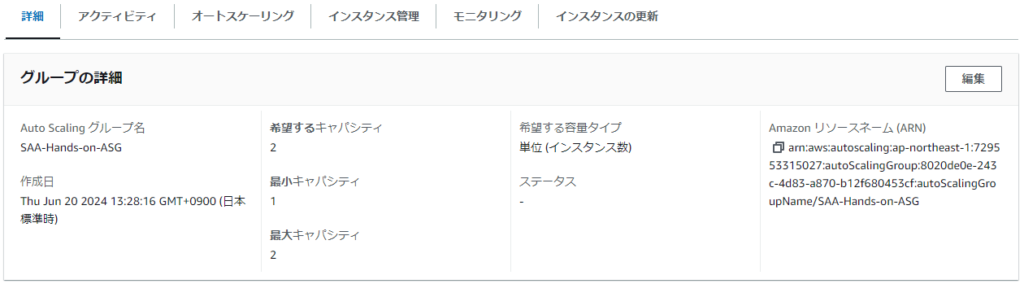
どうやったら解決できんのこれ(´;ω;`) 仕方のない仕様・・? と思ったら、これもCloudWatchの5分間隔の弊害だった><
10分近く待ったら希望するキャパシティが1に戻ってた;; 勝手に希望を変えるんじゃないよ・・・(人の代理で?;
(5分ちょいすぎに速攻でyesをkillしても、次に反応するのが次の5分後だったからみたい)
そしてそこからさらにDrainingにも300秒?かかり・・・死ぬほどかったるい;;;;;;;
スケーリングクールダウン
クールダウン期間:前回のスケーリングが完了する前に、Auto Scalingグループが追加のインスタンスを起動したり終了したりしないようにする
シンプルスケーリングポリシーで優先クールダウン期間を設定(ASGのデフォルトクールダウン期間よりも優先される)
例:デフォ300秒は長すぎ→スケールインポリシーに「180秒」を設定する→コスト削減につながる(かもね)
※もし何度もスケールアップ/ダウンを繰り返すようなら、
ASG側(スケーリングポリシー)のクールダウン期間
CloudWatch側のアラーム期間
双方の調整で、意図する振る舞いに近づけること!
高度な設定
終了ポリシー(Termination Policy)スケールイン時のインスタンス削除ルール
デフォルトの振る舞い
1.インスタンスの数が最も多いAZを探す
2.AZに選択可能な複数のインスタンスがある場合、起動テンプレートが最も古いものを削除
ASGは、デフォルトでAZ間のインスタンス数のバランスを取ろうとする!
ライフサイクルフック
ペンディングフック(Pending状態からInService状態に移行する間に、追加処理のふるまいを追加)
ターミネーティングフック(Terminating状態からInService状態に移行する間に、追加処理のふるまいを追加)
起動テンプレート と 起動設定
両方に共通
AMIのID、インスタンスタイプ、キーペア、SG、EC2起動用パラメータ(タグ、ユーザーデータ等)
起動設定(Launch Configuration)レガシー
変更したい場合は、毎回新しい設定を作り直す必要がある
起動テンプレート(Launch Template)新しい
複数のバージョンを持つことができる
パラメータのサブセット(再利用や継承のための部分的な設定)の作成
オンデマンドとスポット、両方のインスタンスを組み合わせたプロビジョニング
T2のアンリミテッドバースト機能が使える
てゆーか、今や起動テンプレートしか選べませんけどww